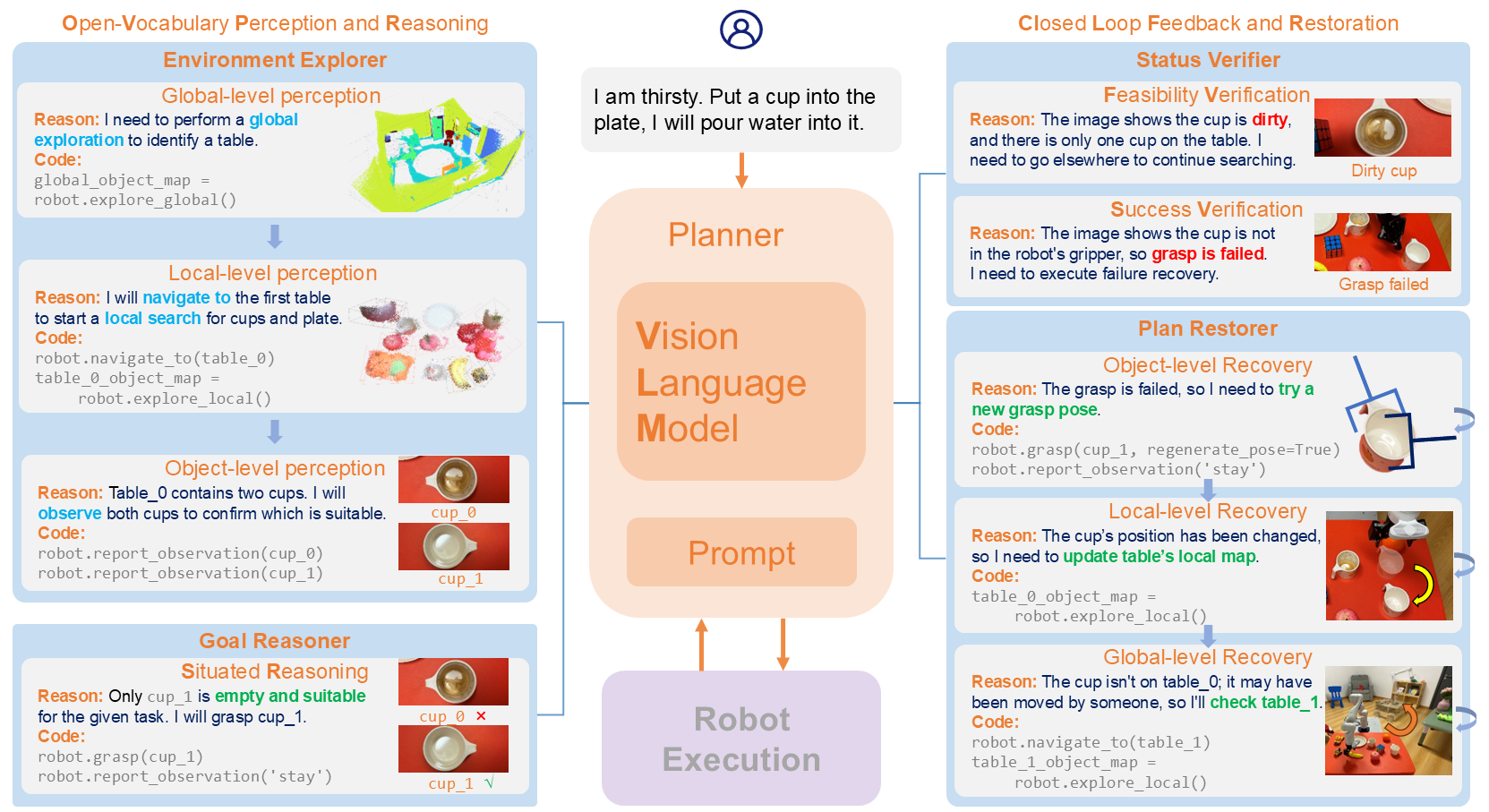
Autonomous robot navigation and manipulation in open environments require reasoning and replanning with closed-loop feedback. In this work, we present COME-robot, the first closed-loop robotic system utilizing the GPT-4V vision-language foundation model for open-ended reasoning and adaptive planning in real-world scenarios. robot incorporates two key innovative modules: (i) a multi-level open-vocabulary perception and situated reasoning module that enables effective exploration of the 3D environment and target object identification using commonsense knowledge and situated information, and (ii) an iterative closed-loop feedback and restoration mechanism that verifies task feasibility, monitors execution success, and traces failure causes across different modules for robust failure recovery. Through comprehensive experiments involving 8 challenging real-world mobile and tabletop manipulation tasks, COME-robot demonstrates a significant improvement in task success rate (~35%) compared to state-of-the-art methods. We further conduct comprehensive analyses to elucidate how COME-robot's design facilitates failure recovery, free-form instruction following, and long-horizon task planning.